
In Storage Spaces, you can set up your Space with a resiliency. This means, when a drive fails, you do not lose your data, not even a portion of it. However, even if you are already running a Storage Space, did you ever put this to a test? And if so, did you do that test before you actually dumped all your data into that Space? Today, we’re going to cover some points you might want to consider before experiencing your first drive failure in production environment.
When a Drive Fails, Resiliency is Gone
The title covers this. If you set your Space to be resilient against 1 drive failing, your resiliency is gone by the time the disk failure occurs. Considering of course, the failure is detected successfully. Detecting a drive failure is not a given, and S.M.A.R.T. isn’t a fire-and-forget. The worst data disasters in production environment often come from the worst-case scenario: A failing disk, that the system has failed to detect as such. When another disk fails with successful detection, the previously failing disk’s issues will manifest. The system will fail to read or write data and will finally figure out that something is really wrong with yet another drive and will degrade the Storage Space. Unfortunately, with Storage Spaces, there is no recovery from this. In different environments, like Intel Raid, the array will disconnect, un-mount and you are free to run recovery tools to maybe attempt to recover your data. Maybe you want to send one of the failed drives to a recovery shop and then attempt to re-mount the array with only 1 disk failed. Not with Storage Spaces. Once the OS detects irrecoverable malfunction, it will degrade the entire Space irrecoverably. The Space will be put into a state that is called unhealthy and there is no way to ever bring it back in a parity environment. Microsoft’s own documentation states:
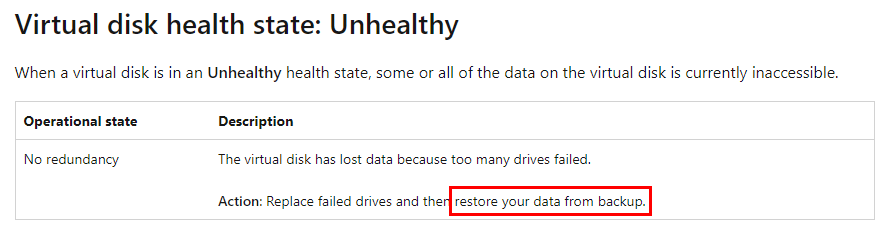
The idea behind this paragraph is – back up your data. Resiliency is not a backup, the array might still fail and it happens more often than you may think.
When a Drive Fails and Your Array Does Not Have Extra Drives
If you set up your Space of 5 Drives in 5 columns, and one of those drives fail, you cannot remove this drive from the Space. Storage Spaces will not permit a change that would result with 4 physical drives being present in a 5-column Space. Your only approach there is to plug another drive into the system, let Storage Spaces recalculate the array and then you’d be able to retire the broken disk. This all has to play out during a degraded state, when you’re most likely to make a mistake. Realize, that plugging in additional drive will probably require you to open the case up, plug additional SATA cable and SATA-power into the new drive. If you accidentally bump into another disk’s cable and unseat it, you will irrecoverably fail your entire Space on Windows startup. A sure-fire way would be to boot into BIOS and make sure all drives are visible there before continuing to boot, but remember – this usually takes place out of work hours, at night, when you’re exhausted and just want the damn thing to work, so you can go to sleep. That’s when you’re most likely to make a mistake. A USB-plugged drive might also not be the best approach. Some drive enclosures are not transparent enough for the system to comfortably fit into a Storage Space use case. So either make sure your array can suffer a disk retirement outright, or be well prepared for the scenario where you have to quickly jump in with additional drive.
When a Drive Fails, You May Not Have Enough Space to Retire It
When a drive fails, the system successfully detects the failure, your resiliency is gone. The way to recover it is to retire the affected drive. When you take the drive out of the array, Storage Spaces will recalculate the entire array so that the data becomes resilient again without the broken drive being used at all. Even if you use higher number of drives than you have columns in your Space, you still might not be able to retire the affected drive. Imagine this – you are running 5 column Storage Space on 6 physical drives. Drives are all 2TB capacity, which means 1.81TB of usable space per. That makes a 6 x 1.81TB of Storage Space capacity, adding up to a total of 10.86TB. Consider, that the Space is running with a 1-drive resiliency. In a 5-column setup, parity eats up 20% of your capacity, regardless of the drive count. This means that out of 10.86TB, about 2.2TB is used for parity across all drives. This leaves about 8.7TB of usable space for all your data. Now, let’s say that you use all of that space, and your array is now full of data. When a drive fails, you will not be able to retire it. Even if your drive count is higher than your column count, you simply do not have any space left to move the data to. For this reason also, Storage Spaces will warn you about insufficient Storage Space capacity long before it is filled up.
Space Recalculation Can Also Result in Failure
Check your Storage Space. It is likely that all your drives will be of the same make and model. If one of them fails, the others could be facing similar failure. Even if you mismatch makes and models to avoid such exposure, you’re still not in the clear. Upon drive failure and recalculation, the entire Storage Space will run at maximum performance of many hours, continuously, recalculating all of the data, to first recover all of the data and then recompute the new layout including parity. This is putting considerable strain on all of the remaining drives, increasing their chances of failure. If any issue has already been looming in one of the remaining drives, the increased strain is more likely to make that issue finally surface and destroy another drive, putting you back to square one, explained in the first paragraph above.